Meeting-Protokolle sind das Gedächtnis jeder Organisation. Budgetentscheidungen, Verantwortlichkeiten, Risiken, Deadlines — alles dokumentiert, abgelegt, vergessen. In Unternehmen — vom Mittelstand bis zum Großkonzern — entstehen pro Projekt dutzende Protokolle aus Steering Committees, Jour Fixes und Statusmeetings. Das Problem: Niemand durchsucht sie systematisch. Stattdessen fragt man Kollegen, erinnert sich ungefähr oder öffnet im besten Fall die Volltextsuche im PDF-Reader.
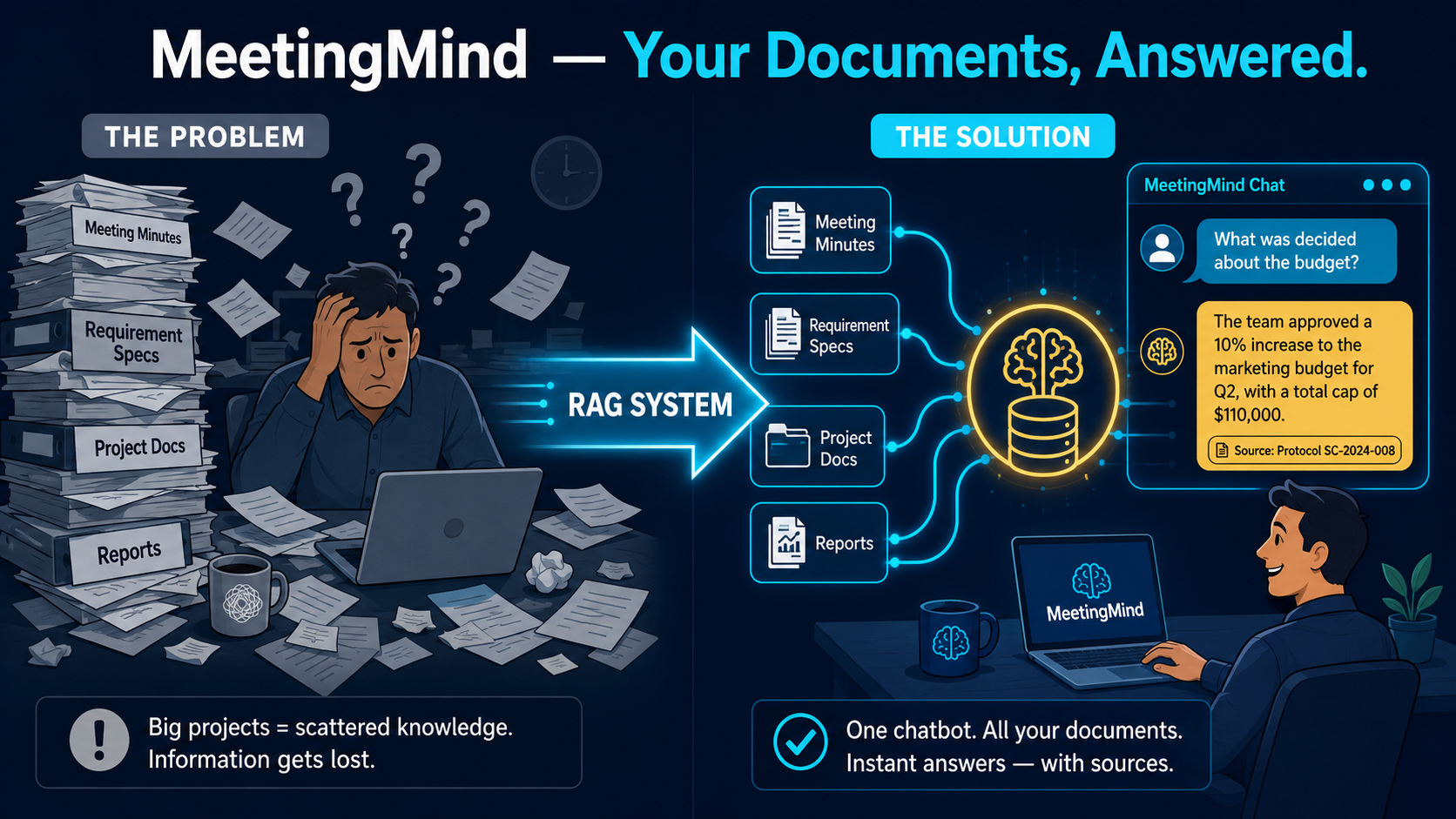
Abbildung 1: Das Problem und die Lösung auf einen Blick: verstreute Dokumente werden zu abrufbarem Wissen — mit Quellenangabe.
Das kostet Zeit, Informationen gehen verloren, Entscheidungen fallen auf lückenhafter Basis. Selbst ein sauber erstelltes Protokoll geht in großen Projekten schnell wieder unter. Das ist keine Theorie, sondern Realität — ich spreche aus Erfahrung. Lange dachte ich: Das muss doch mit klaren Prozessen, Vorlagen und Regeln lösbar sein. Aber ganz ehrlich: In einem Projekt mit hunderten Mitarbeitern und zig unterschiedlich arbeitenden Teams stoßen solche Ansätze schnell an ihre Grenzen. Mit heutiger Technologie aber ist das Problem lösbar — und genau das habe ich mir zur Aufgabe gemacht.
Wissen geht selten verloren, weil es fehlt — sondern weil es nicht abrufbar ist. Ob aus abgelegten Dokumenten nutzbares Wissen wird, entscheidet nicht die Menge der Daten, sondern die Technologie, mit der man sie erschließt.
Suche ist nicht gleich Verstehen
Volltextsuche findet Wörter. Sie findet nicht die Antwort auf “Warum wurde das Projektbudget erhöht?” oder “Welche Risiken haben wir im Q1 identifiziert?”. Dafür braucht es ein System, das Dokumente nicht nur durchsucht, sondern versteht — und in natürlicher Sprache antwortet, mit Quellenangabe. Genau das leistet Retrieval-Augmented Generation (RAG): eine Kombination aus intelligenter Suche und Sprachmodell, die relevante Passagen findet und daraus eine präzise Antwort formuliert.
MeetingMind: RAG für Mittelstand und Großkonzern — vollständig lokal
Mit MeetingMind habe ich ein RAG-System gebaut, das Meeting-Protokolle per natürlicher Sprache durchsuchbar macht. Der entscheidende Unterschied zu generischen Lösungen: Es läuft vollständig on-premise. Kein Cloud-Upload, kein externer API-Call, keine Daten die das Unternehmen verlassen. DSGVO-Konformität ist keine Zusatzfunktion — sie ist die Architektur.
Ein Beispiel: Auf die Frage “Welche Probleme gab es mit der SAP-Lizenz und wie wurden sie gelöst?” durchsucht das System 10 Protokolle und antwortet in Sekunden: 6 Wochen Lieferverzögerung, Eskalation beim SAP-Vertrieb, neues Lieferdatum 10. Juni 2024 — mit exakter Quellenangabe (Protokoll SC-2024-008). Eine Frage, eine Antwort, eine Quelle.
Die Kernentscheidung: Chunking nach Tagesordnungspunkten
Standard-RAG-Systeme teilen Dokumente nach Token-Anzahl — alle 512 Token ein neuer Block. Für Meeting-Protokolle ist das fatal: ein Beschluss wird mitten im Satz getrennt, eine Maßnahmentabelle zerrissen, der Kontext zerstört.
MeetingMind chunked anders. Die Grenzen liegen an strukturellen Dokumentmarkierungen: Tagesordnungspunkte, Beschlussboxen, Maßnahmenlisten. Jeder Chunk enthält zusätzlich Metadaten — Protokoll-ID, Datum, Teilnehmer — die bei der Antwortgenerierung als Kontext mitgegeben werden.
Das klingt wie ein Detail, ist aber der erste und wichtigste von drei Hebeln, an denen ein RAG-System steht oder fällt: Dokumente einfach stumpf zu zerschneiden funktioniert nicht — man muss ihre Struktur vorher verstehen. Die gute Nachricht: Das ist kein Hexenwerk, sondern mit klaren Vorlagen und Prozessen beherrschbar. Welche zwei Hebel danach kommen, zeigt die Evaluation.
Was die Evaluation zeigt: Der Engpass ist nicht die Suche
Der spannendste Teil war nicht der Bau, sondern die systematische Evaluation: 15 Testfragen, ein Golden Dataset mit erwarteten Antworten, drei Messmethoden, drei Sprachmodelle.
| Modell | Größe | Antwort-Genauigkeit | Retrieval-Trefferquote |
|---|---|---|---|
| llama3 | 8B | 67 % (10/15) | 100 % (15/15) |
| llama3.1 | 8B | 80 % (12/15) | 100 % (15/15) |
| llama3.2 | 3B | 60 % (9/15) | 100 % (15/15) |
Wichtig: zwei verschiedene Metriken. Die Trefferquote misst, ob die richtige Quelle gefunden wurde (Retrieval); die Genauigkeit, ob die daraus formulierte Antwort stimmt (Generierung).
Bei jeder einzelnen Frage wurde die richtige Quelle gefunden — 15 von 15. Die Suche funktioniert perfekt. Ist eine Antwort trotzdem falsch, liegt es am Sprachmodell, das die vorhandene Information nicht korrekt herausliest. Besonders aussagekräftig: Alle drei Modelle bekamen exakt dieselben Chunks — nur die Generierung daraus unterschied sich.
Der Engpass eines RAG-Systems liegt selten dort, wo man ihn vermutet. Nicht die Suche ist das Problem, sondern was das Sprachmodell aus dem Gefundenen macht.
Das hat direkte Business-Relevanz, denn es zeigt: Ein RAG-System optimiert man nicht an einer einzigen Stellschraube, sondern an drei Hebeln, in der richtigen Reihenfolge.
Hebel 1: das Chunking. Der wichtigste, und er kommt zuerst. Wie die Art, Dokumente zu zerlegen, über jede Antwort entscheidet, ist oben gezeigt — beherrschbar mit klaren Vorlagen und Prozessen.
Hebel 2: die richtige Kontextmenge (top-k). Mehr Suchergebnisse klingt intuitiv besser — ist es aber nicht. Von 10 auf 15 Chunks erhöht, sank die Genauigkeit von 60 % auf 53 %. Das Modell verliert bei zu viel Kontext den Fokus (“Lost in the Middle”). Es geht nicht um mehr, sondern um die richtige Menge.
Hebel 3: die Modellwahl. Erst wenn Chunking und Kontextmenge sitzen, lohnt sich der Blick aufs Modell — und zwar nicht mit dem größten zuerst, sondern herantastend, wie bei der Hyperparameter-Optimierung. Allein der Wechsel von llama3 auf llama3.1 (eine Zeile Code) brachte 13 Prozentpunkte mehr Genauigkeit, ohne ein größeres, teureres Modell. Bemerkenswert: llama3.2 (das “neuere” Modell) war schlechter — ein verkleinertes Edge-Modell für Mobilgeräte, nicht für Faktenextraktion aus langem Kontext. Neuer heißt nicht besser.
Die Lehre: Wer in “bessere Suche” investiert, obwohl die Suche bereits zu 100 % trifft, optimiert am falschen Ende. Die Hebel liegen woanders — und kosten oft weniger, als man denkt.
Typische Fehler bei RAG-Projekten
Auf den eigenen Testdaten optimieren. Löst ein Prompt-Tweak gezielt eine Testfrage, verbessert man die Metrik, nicht das System. Ich habe drei falsche Antworten bewusst als dokumentierte Grenzen stehen gelassen, statt sie per maßgeschneidertem Prompt zu “lösen” — das wäre Overfitting.
Messung unterschätzen. Naives Substring-Matching ergab 33 %, Keyword-Matching 80 % — dieselben Antworten, zwei völlig verschiedene Geschichten. Ohne die richtige Metrik trifft man falsche Optimierungsentscheidungen.
Self-Hosted ist kein Nice-to-have
Jedes Dokument in einer Cloud-API unterliegt fremder Datenverarbeitung. Für Protokolle mit Budgetzahlen, Personalentscheidungen und strategischen Beschlüssen ist das vielerorts ein K.O.-Kriterium. MeetingMind braucht nur drei lokale Komponenten: Ollama (Sprachmodell + Embeddings), Qdrant (Vektordatenbank) und Python. Keine Cloud-Accounts, keine API-Keys, keine Lizenz- oder Nutzungsgebühren — die Installation passt in vier Terminal-Befehle. Zur ehrlichen Rechnung gehört aber: Statt laufender Lizenzkosten fallen Hardwarekosten an. Wer Modelle lokal betreibt, braucht eine passende Maschine (in der Regel mit GPU). Für den Mittelstand wie für den Großkonzern bleibt das meist die günstigere und sicherere Wahl — die Kosten sind nur an anderer Stelle.
Ausblick
Das System beweist die Machbarkeit. Für den Produktiveinsatz folgen konkrete Schritte: ein Web-Interface (FastAPI + React), Docker Compose für Ein-Klick-Deployment, Metadaten-Filter nach Zeitraum oder Verantwortlichen. Der Stack ist bewusst erweiterbar: Qdrant unterstützt Hybrid Search (Vektor + Keyword), und stärkere Modelle wie Llama 3.3 70B oder Qwen 3 könnten verbleibende Halluzinationen weiter reduzieren — passende Hardware vorausgesetzt.
Fazit
Meeting-Protokolle durchsuchbar zu machen ist kein Forschungsprojekt mehr — es ist ein Engineering-Problem mit konkreter Lösung. RAG funktioniert, die Suche ist gelöst (100 % Trefferquote), und der verbleibende Engpass (das Sprachmodell) verbessert sich mit jeder Modellgeneration. Ob Mittelstand oder Großkonzern, das heißt: Wissensmanagement ohne Cloud-Risiko, auf Open-Source-Komponenten, auf eigener Hardware. Kein Protokoll verlässt das Haus.
Warum ich das gebaut habe? Mein Ziel war eine Machbarkeitsanalyse: Lässt sich ein Problem, das ich aus der Praxis nur zu gut kenne, mit heutiger Technologie tatsächlich lösen? Die Antwort ist ja. Ein System, das Wissen nicht verliert, sondern auf Abruf bereitstellt, macht Projektarbeit messbar effizienter, die Ergebnisse belastbarer und die Zusammenarbeit reibungsloser. Aus verstreuten Dokumenten wird abrufbares Wissen — genau das war die Aufgabe, die ich mir gestellt hatte.
Code & Ressourcen
Wenn du selbst reinschauen möchtest – der komplette Code ist auf GitLab:
🔗 https://git.tellaev.de/stellaev/MeetingMing_RAG
Dort findest du:
- Python-Projekt – die komplette RAG-Pipeline (Chunking, Ingest, Query)
- Datensatz – synthetische Meeting-Protokolle (Projekt ATLAS)
- Tests – Eval-Harness mit Golden Dataset und Metriken
Kontakt
Fragen? Feedback? Eigene Erfahrungen teilen? Schreib mir gerne: