Warum Ihr Unternehmen seine Meeting-Protokolle nicht lesen kann — und wie RAG das ändert
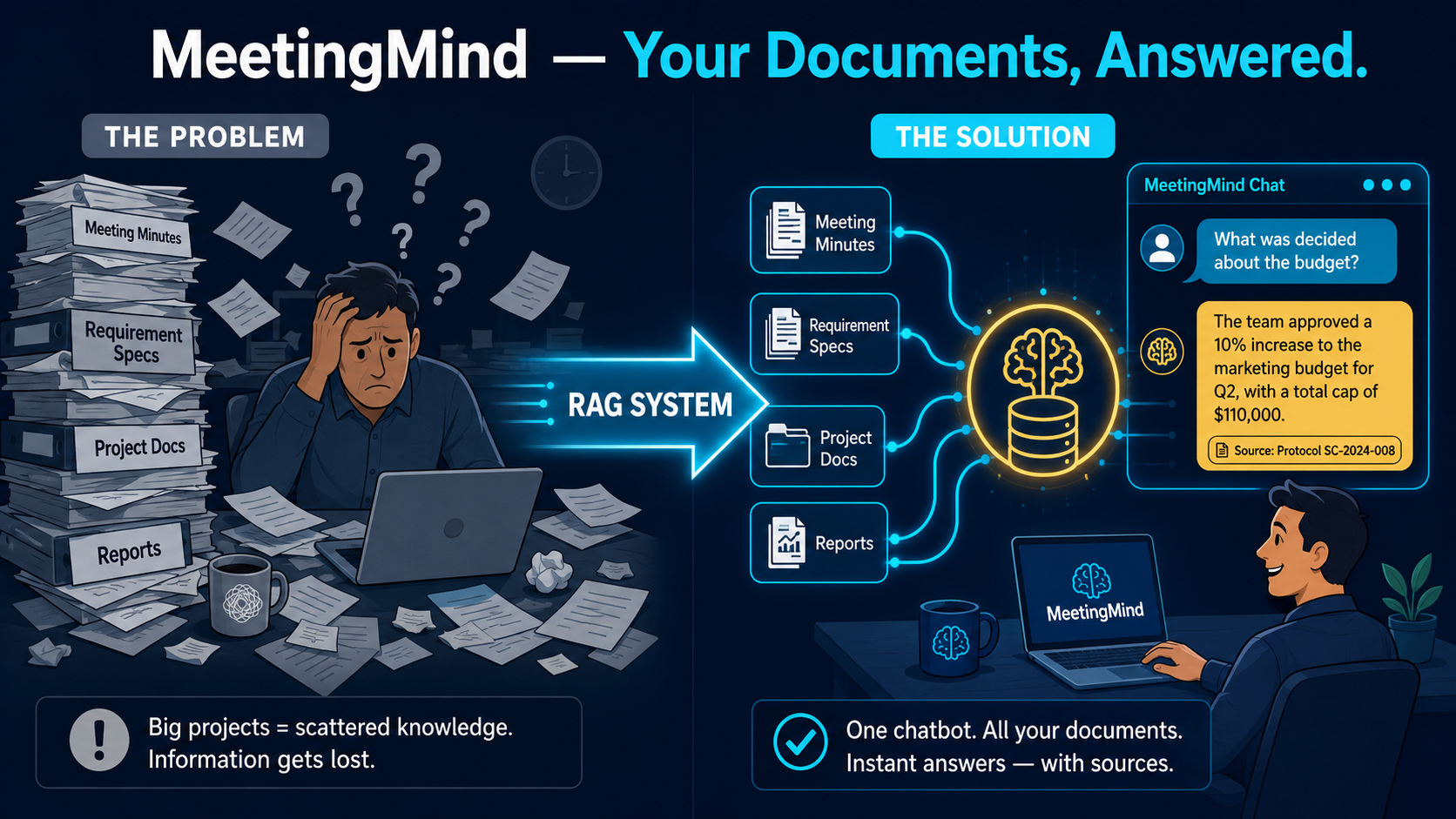
Meeting-Protokolle sind das Gedächtnis jeder Organisation. Budgetentscheidungen, Verantwortlichkeiten, Risiken, Deadlines — alles dokumentiert, abgelegt, vergessen. In Unternehmen — vom Mittelstand bis zum Großkonzern — entstehen pro Projekt dutzende Protokolle aus Steering Committees, Jour Fixes und Statusmeetings. Das Problem: Niemand durchsucht sie systematisch. Stattdessen fragt man Kollegen, erinnert sich ungefähr oder öffnet im besten Fall die Volltextsuche im PDF-Reader.
Abbildung 1: Das Problem und die Lösung auf einen Blick: verstreute Dokumente werden zu abrufbarem Wissen — mit Quellenangabe.