540.000 Transaktionen auswerten – mit den richtigen Werkzeugen schneller als gedacht
Viele Unternehmen sitzen auf wertvollen Daten, ohne sie zu nutzen. Mit den richtigen Werkzeugen und Data-Science-Know-how lassen sich daraus schnell Erkenntnisse gewinnen, die direkt in strategische Entscheidungen einfließen können.
90% der Kunden, die einen bestimmten Teelichthalter kauften, bestellten auch eine Etagere. Diese Erkenntnis steckte die ganze Zeit in den Daten – aber erst die richtige Analysemethode machte sie sichtbar.
Ich habe einen realen Datensatz eines britischen Online-Händlers genommen – rund 540.000 Transaktionen, 4.335 Kunden, 3.660 Produkte – und ihn aus drei verschiedenen analytischen Perspektiven untersucht. Bewusst mit drei Datenbank-Technologien, weil jede für andere Fragestellungen optimiert ist: PostgreSQL (relational), MongoDB (dokumentbasiert) und Neo4j (graphbasiert). Alle drei lassen sich in einer zentralen Analyse-Plattform wie KNIME integrieren – je nach Fragestellung greift man auf die Datenbank zurück, mit der sich die Analyse am effizientesten durchführen lässt. Nicht die Daten ändern sich, sondern die Perspektive – und damit die Erkenntnisse.
Dieser Artikel beschreibt die Modellierungsansätze und die Ergebnisse – nicht als Programmier-Tutorial, sondern als Beispiel dafür, was sich aus vorhandenen Daten herausholen lässt, wenn man die richtigen Werkzeuge kennt.
Warum drei Perspektiven?
Jede Datenbanktechnologie hat andere Stärken. Zu wissen, welche Technologie welche Frage am besten beantwortet, ist der Schlüssel zu schnellen Ergebnissen.
- Relationale Datenbanken wie PostgreSQL: stark bei strukturierten Auswertungen – Summen, Rankings, Gruppierungen. Die Frage „Wer sind meine Top-Kunden nach Umsatz?" ist ein Einzeiler.
- Dokumentdatenbanken wie MongoDB: speichern eine Bestellung als zusammenhängende Einheit statt über mehrere Tabellen verteilt. Ideal für Fragen wie: Wie groß ist ein typischer Warenkorb?
- Graphdatenbanken wie Neo4j: modellieren Daten als Netzwerk aus Beziehungen. Perfekt für: Kunden, die Produkt A kauften – was kauften sie noch?
Die zentrale These dieses Projekts: Dieselben Rohdaten liefern je nach Modellierung und Technologie unterschiedliche Erkenntnisse. Nicht weil die Daten anders sind, sondern weil das Denkmodell andere Fragen ermöglicht.
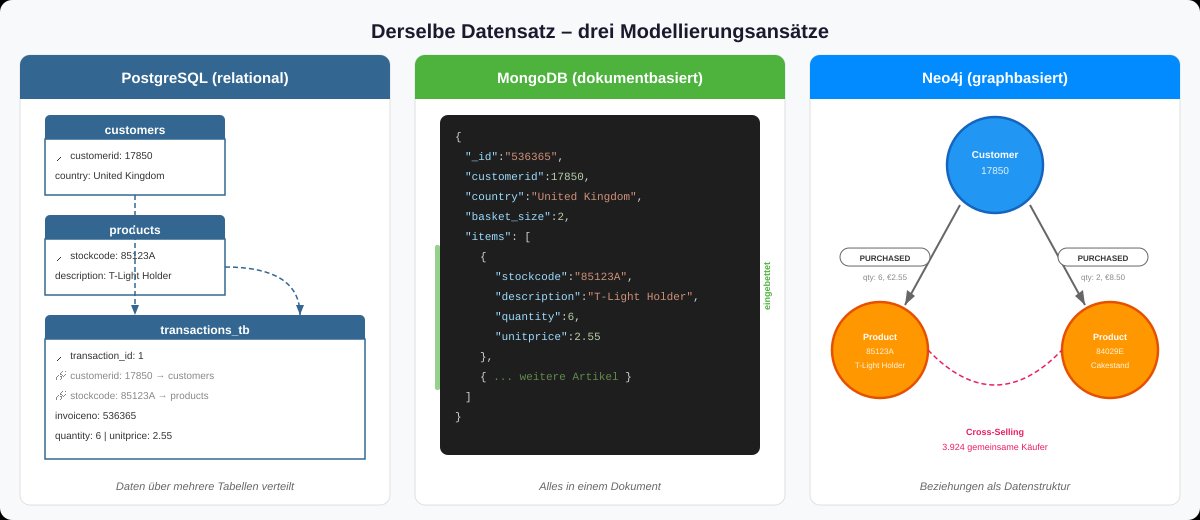 Abbildung: Derselbe Datensatz, drei Modellierungsansätze – jede Struktur beantwortet andere Fragen.
Abbildung: Derselbe Datensatz, drei Modellierungsansätze – jede Struktur beantwortet andere Fragen.
Methodik: Vom Rohdatensatz zur Analyse
Datenbereinigung
Vor jeder Analyse steht die Datenqualität. Der Rohdatensatz enthielt mehrere Probleme, die typisch für reale E-Commerce-Daten sind:
Stornierungen und negative Stückzahlen machten rund 2% der Datensätze aus. Stornierungen waren am „C"-Präfix in der Rechnungsnummer erkennbar. Zusätzlich enthielt der Datensatz Transaktionen mit negativen Stückzahlen ohne „C"-Präfix – vermutlich Retouren oder Korrekturen, die nicht einheitlich gekennzeichnet wurden. Beide wurden separiert, um Umsatzkennzahlen nicht zu verfälschen.
Fehlende Kundenzuordnungen betrafen rund 25% der Transaktionen – vermutlich Gastkäufe. Für RFM-Analyse und Cross-Selling wurden sie herausgefiltert, da diese Methoden eine eindeutige Kundenzuordnung voraussetzen. Für die Warenkorbanalyse blieben sie erhalten, weil dort nur die Bestellung selbst zählt, nicht wer bestellt hat.
Nicht-Produkt-Einträge wie Portokosten oder Bankgebühren hatten eigene Artikelcodes und wurden entfernt, da sie keine echten Kaufentscheidungen repräsentieren.
Die gesamte Bereinigung wurde mit KNIME als visueller ETL-Workflow umgesetzt – reproduzierbar und bei neuen Datenlieferungen automatisch wiederholbar.
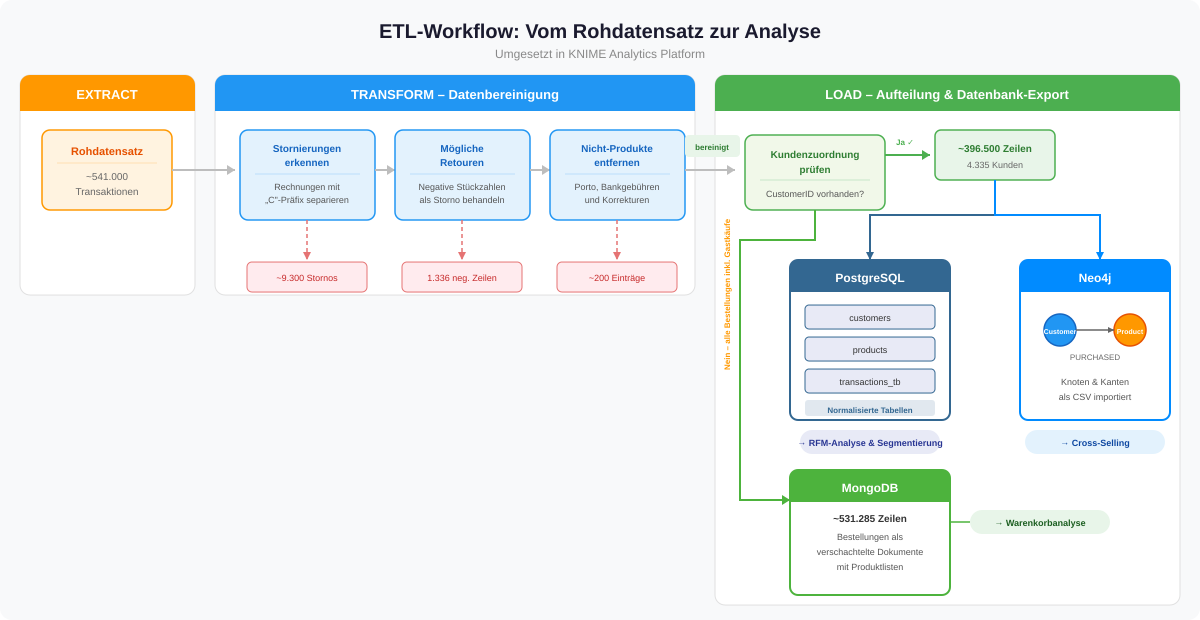 Abbildung: Der KNIME-Workflow zeigt die Bereinigungsschritte und die Aufteilung der Daten für die drei Datenbanken.
Abbildung: Der KNIME-Workflow zeigt die Bereinigungsschritte und die Aufteilung der Daten für die drei Datenbanken.
Datenmodellierung: Drei Modelle für denselben Datensatz
Der entscheidende methodische Schritt ist die Modellierung – also die Frage, wie dieselben Rohdaten für die jeweilige Technologie aufbereitet werden.
Relational (PostgreSQL): Die Daten werden in drei normalisierte Tabellen aufgeteilt – Kunden, Produkte und Transaktionen. Jede Transaktion verweist per Fremdschlüssel auf den zugehörigen Kunden und das Produkt. Diese Struktur erzwingt Konsistenz und ermöglicht effiziente Aggregationen über große Datenmengen.
Dokumentbasiert (MongoDB): Die flachen Transaktionszeilen werden zu verschachtelten Dokumenten transformiert. Pro Bestellung entsteht ein Dokument, das alle gekauften Produkte als eingebettete Liste enthält – der Warenkorb als natürliche Einheit, ohne JOINs.
Graphbasiert (Neo4j): Kunden und Produkte werden als Knoten dargestellt, Kaufvorgänge als gerichtete Kanten dazwischen. Jede Kante trägt Attribute wie Menge und Preis. Beziehungen zwischen Entitäten werden zum Kern der Datenstruktur.
Perspektive 1: Kundensegmentierung mit RFM-Analyse (PostgreSQL)
Die Methode
Die RFM-Analyse ist ein bewährtes Verfahren aus dem Direktmarketing, mit dem jeder Kunde anhand von drei Verhaltensdimensionen bewertet wird:
Recency misst, wie viele Tage seit dem letzten Einkauf vergangen sind. Kunden, die kürzlich gekauft haben, sind empfänglicher für Angebote und wahrscheinlicher aktiv.
Frequency zählt die Gesamtzahl der Bestellungen. Häufige Käufer sind in der Regel loyaler und haben eine stärkere Bindung an den Händler.
Monetary summiert den Gesamtumsatz. Kunden mit hohem Umsatz sind wirtschaftlich wertvoller – auch wenn hoher Umsatz allein nicht zwingend hohe Loyalität bedeutet.
Jede Dimension wird in fünf Gruppen eingeteilt (Quintile), sodass jeder Kunde in meinem Beispiel einen Score von 1 bis 5 pro Dimension erhält. Aus der Kombination dieser drei Scores entstehen Kundensegmente.
Warum relational?
Die gesamte RFM-Berechnung – von der Aggregation der Rohdaten über die Quintil-Einteilung bis zur Segmentzuweisung – lässt sich in PostgreSQL als eine einzige Abfrage umsetzen. Kein externer Code, keine Zwischenspeicherung, jederzeit reproduzierbar. Wer strukturierte Transaktionsdaten hat, kommt mit diesem Ansatz innerhalb von Minuten zu einer vollständigen Kundensegmentierung.
Ergebnisse
Die Segmentierung der 4.335 Kunden ergab sechs Gruppen:
| Segment | Logik | Kunden | Anteil | Bedeutung |
|---|---|---|---|---|
| VIP/Loyal | R≥4, F≥4, M≥4 | 950 | 22% | In allen drei Dimensionen top – kürzlich aktiv, kauft häufig, hoher Umsatz |
| Potenzial | R≥4, F≥2 (Rest) | 647 | 15% | Kürzlich aktiv mit moderater Kaufhäufigkeit, aber noch nicht in allen Dimensionen top |
| Neukunden | R≥4, F=1 | 137 | 3% | Kürzlich erstmals gekauft – am Anfang der Customer Journey |
| Abwanderungsgefährdet | R≤2, F≥3 | 653 | 15% | War früher häufiger Käufer, ist aber lange nicht mehr aktiv |
| Inaktiv | R≤2, F≤2 | 1.081 | 25% | Selten gekauft und lange nicht mehr aktiv |
| Sonstige | R=3 (Rest) | 867 | 20% | Mittlerer Recency-Score – zwischen aktiv und inaktiv |
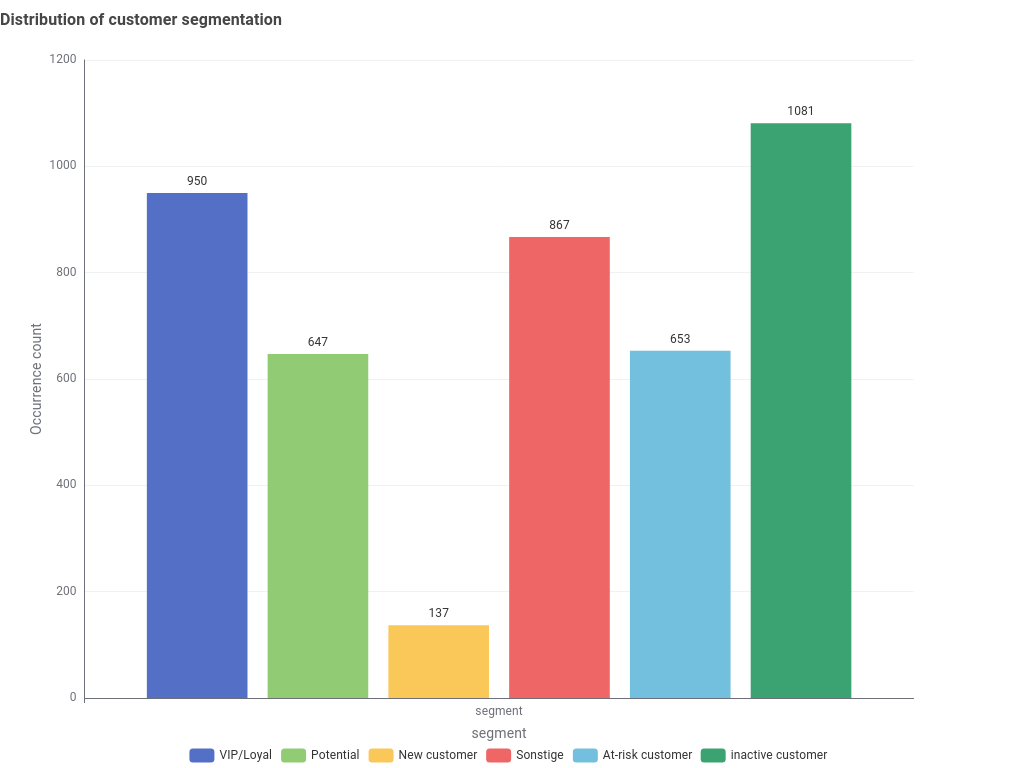
Abbildung: Verteilung der Kundensegmente nach RFM-Analyse.
Die 867 „Sonstige"-Kunden (20%) haben einen mittleren Recency-Score (R=3) und fallen damit zwischen die Segmente – weder kürzlich aktiv genug für „Potenzial" oder „Neukunden", noch lange genug inaktiv für „Abwanderungsgefährdet" oder „Inaktiv". In der Praxis würde man diese Lücke entweder durch feinere CASE-Regeln schließen. Alternativ können diese Kunden mittels datengetriebener Methoden wie K-Means-Clustering klassifiziert werden.
Die wichtigste Erkenntnis aus den Daten: Die Kombination aus nur 3% Neukunden und 25% Inaktiven bedeutet, dass die aktive Kundenbasis schrumpft. Der Fokus sollte auf den 15% abwanderungsgefährdeten Kunden liegen – sie haben bereits eine Kaufhistorie und waren früher häufige Käufer. Gezielte Maßnahmen wie personalisierte Rabatte oder Erinnerungsmails können hier den größten ROI erzielen, weil die Akquisekosten deutlich niedriger sind als bei Neukunden.
Perspektive 2: Warenkorbanalyse (MongoDB)
Die Methode
Die Warenkorbanalyse betrachtet nicht den Kunden über die Zeit, sondern die einzelne Bestellung als analytische Einheit. Sie beantwortet Fragen wie: Wie viele Produkte enthält eine typische Bestellung? Wie hoch ist der durchschnittliche Bestellwert? Welche Produkte sind Bestseller?
Diese Perspektive ergänzt die RFM-Analyse: Während RFM den Kunden klassifiziert, klassifiziert die Warenkorbanalyse das Kaufverhalten pro Transaktion.
Warum dokumentbasiert?
In einer relationalen Datenbank liegen die Daten normalisiert vor: Jede Bestellposition ist eine eigene Zeile. Um einen vollständigen Warenkorb zu sehen, muss man erst alle Positionen einer Bestellung zusammenführen und die Produktinformationen dazuholen – man rekonstruiert den Warenkorb bei jeder Abfrage aus Einzelteilen. In der Praxis bedeutet das: Abfragen werden schnell komplex, sind fehleranfälliger, schwerer zu lesen und aufwendig in der Wartung. Jede Anpassung an der Analyse erfordert Änderungen an mehreren Stellen gleichzeitig.
In MongoDB werden die Bestellungen einmalig als verschachtelte Dokumente aufbereitet – jede Bestellung enthält ihre komplette Produktliste und kann beliebig um weitere Informationen ergänzt werden, etwa Kundenhistorie, Kategorien oder Bewertungen. Alle relevanten Daten zu einer Bestellung oder einem Artikel liegen an einer Stelle. Anstatt bei jeder Analyse Informationen aus mehreren Quellen zusammenzusuchen, greift man direkt auf ein vollständiges Dokument zu. Und wenn später neue Fragestellungen hinzukommen, lässt sich die Dokumentstruktur flexibel erweitern – ohne bestehende Analysen anpassen zu müssen.
Ergebnisse
Die Kernzahlen auf einen Blick:
| Kennzahl | Wert |
|---|---|
| Durchschnittliche Warenkorbgröße | 26 Artikel |
| Durchschnittlicher Bestellwert | ~514 € |
| Häufigste Warenkorbgröße | 1 Artikel (2.374 Bestellungen) |
| Maximale Warenkorbgröße | 1.114 Artikel |
| Anzahl Warenkörbe gesamt | 20.728 |
Die Zahlen zeigen ein klares Bild: Obwohl der Durchschnitt bei 26 Artikeln liegt, ist die häufigste Warenkorbgröße 1 Artikel. Der hohe Durchschnitt wird durch wenige Großbestellungen verzerrt. Ergebnis: Der Händler bedient zwei fundamental verschiedene Kundentypen – Einzelkäufer und Großabnehmer.
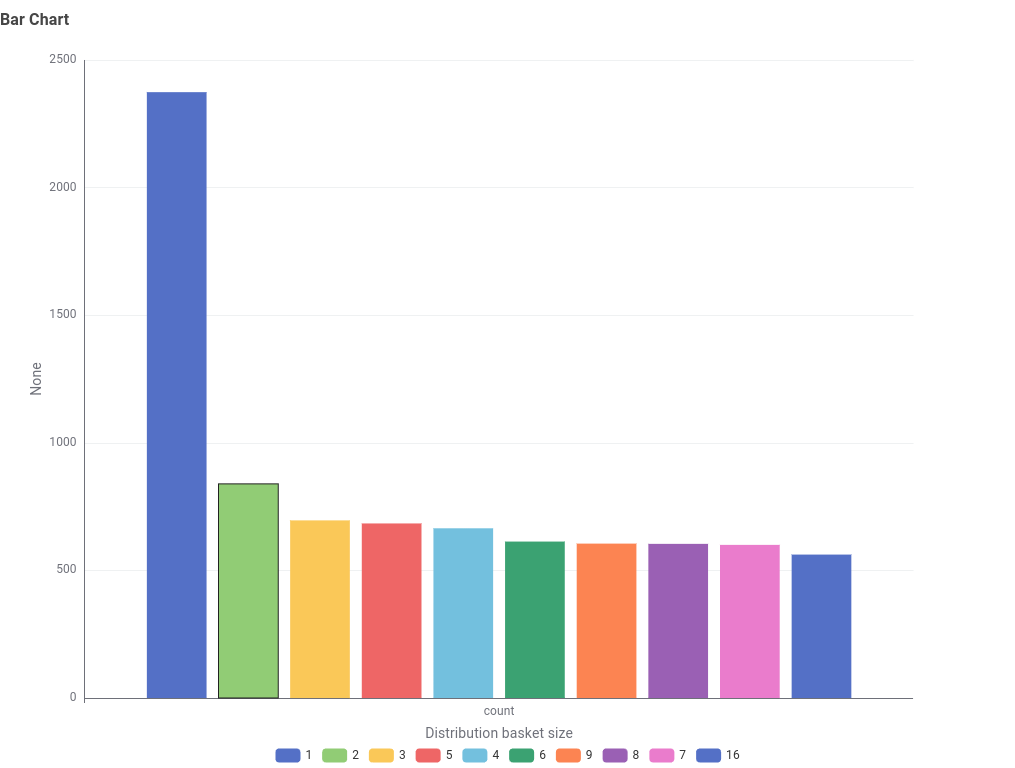 Abbildung: Die Verteilung der Warenkorbgrößen zeigt zwei deutlich unterschiedliche Kundentypen.
Abbildung: Die Verteilung der Warenkorbgrößen zeigt zwei deutlich unterschiedliche Kundentypen.
Bei den Bestsellern dominiert der „White Hanging Heart T-Light Holder" mit über 2.200 Bestellungen, gefolgt von mehreren Produkten der RETROSPOT-Linie – ein Muster, das in Perspektive 3 (Neo4j) erneut auftaucht.
Perspektive 3: Cross-Selling-Empfehlungen (Neo4j)
Die Methode
Cross-Selling beantwortet die Frage: Kunden, die Produkt X gekauft haben – was haben sie noch gekauft? Das Prinzip ist von Amazon und anderen großen Plattformen bekannt („Kunden kauften auch…"), basiert aber auf einer Graph-Traversierung: Man sucht alle Pfade von einem Produkt über gemeinsame Kunden zu anderen Produkten.
Warum graphbasiert?
In einer Graphdatenbank sind Kunden und Produkte Knoten, Käufe sind Beziehungen. Die Cross-Selling-Frage ist eine Zwei-Hop-Traversierung: Vom Referenzprodukt über gemeinsame Kunden zu anderen Produkten. In einer relationalen Datenbank müsste man dafür einen Self-Join auf der Transaktionstabelle durchführen – möglich, aber weder intuitiv noch performant bei wachsenden Datenmengen.
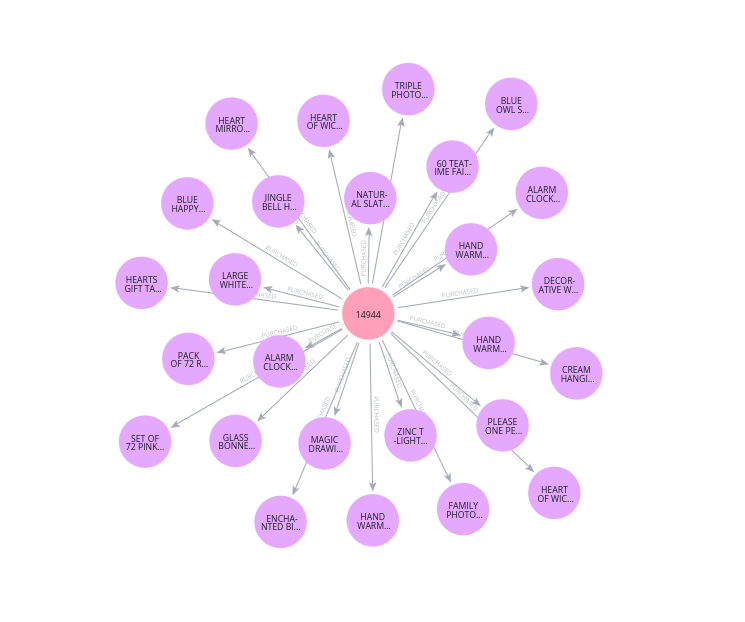 Abbildung: Ausschnitt des Produktnetzwerks in Neo4j. Jede Verbindung zeigt, wie viele gemeinsame Käufer zwei Produkte haben.
Abbildung: Ausschnitt des Produktnetzwerks in Neo4j. Jede Verbindung zeigt, wie viele gemeinsame Käufer zwei Produkte haben.
Ergebnisse
Ausgehend vom Bestseller (dem Teelichthalter) zeigt die Analyse klare Produktpaare:
| Produktpaar | Gemeinsame Käufer |
|---|---|
| Teelichthalter ↔ Etagere | 3.924 |
| Teelichthalter ↔ RETROSPOT Lunch Bag | 3.780+ |
| Teelichthalter ↔ RETROSPOT Jumbo Bag | 3.700+ |
| Teelichthalter ↔ Bilderrahmen | 3.600+ |
| Teelichthalter ↔ Party-Dekoration | 3.500+ |
Was in einer relationalen Datenbank eine aufwendige Konstruktion erfordert hätte, lieferte Neo4j mit einer einzigen Abfrage auf die bestehende Graphstruktur. Und die Ergebnisse sind eindeutig: Bei 4.335 Kunden insgesamt bedeuten 3.924 gemeinsame Käufer, dass über 90% aller Kunden, die den Teelichthalter kauften, auch die Etagere bestellt haben. Das ist kein statistisches Rauschen, sondern ein klares Signal für eine Produktbündelung.
Das Gesamtbild: Was keine einzelne Perspektive allein zeigt
Die eigentliche Erkenntnis liegt in der Kombination der drei Analysen:
PostgreSQL beantwortet WER – 950 VIP-Kunden tragen den Umsatz, 1.081 inaktive Kunden sind verloren, 653 drohen abzuwandern.
MongoDB beantwortet WAS – die meisten Bestellungen sind Einzelkäufe, obwohl der Durchschnitt bei 26 Artikeln liegt.
Neo4j beantwortet WIE Produkte zusammenhängen – der Teelichthalter und die Etagere bilden das stärkste Produktpaar, die RETROSPOT-Linie ist über mehrere Cross-Selling-Beziehungen vernetzt.
Die RETROSPOT-Produktlinie ist dabei der rote Faden durch alle drei Perspektiven: Sie erscheint als Bestseller in der Warenkorbanalyse, als Cross-Selling-Partner im Produktnetzwerk und im Kaufverhalten der VIP-Kunden.
Alle drei Analysen entstanden auf Basis desselben bereinigten Datensatzes. Der Vorteil: Datenbanken mit unterschiedlichen Stärken lassen sich in einer Plattform wie KNIME gemeinsam nutzen – ohne für jede Fragestellung eine separate Infrastruktur aufbauen zu müssen. Die Ergebnisse sprechen für sich: Kundensegmente, Warenkorbmuster und Produktbeziehungen – alles aus denselben Transaktionsdaten.
Fazit: Mit den richtigen Werkzeugen schnelle Ergebnisse – auch bei großen Datenmengen
540.000 Transaktionen, drei Datenbanken, konkrete Antworten auf geschäftsrelevante Fragen. Die Daten dafür waren bereits vorhanden – sie mussten nur richtig ausgewertet werden. Viele Unternehmen scheuen sich davor, ihre Datenmengen systematisch zu analysieren, weil sie den Aufwand überschätzen. Die richtige Kombination aus Methodik, Werkzeugen und Data-Science-Know-how macht den Unterschied – und die Ergebnisse kommen schneller als erwartet.
Code & Ressourcen
Wenn du selbst reinschauen möchtest – die komplette Umsetzung liegt auf meinem GitLab:
🔗 https://git.tellaev.de/stellaev/ecommerce-purchase-analysis
Dort findest du:
- KNIME-Workflow (.knwf)
- Abfragen für PostgreSQL, MongoDB und Neo4j
- Den verwendeten Datensatz
Kontakt
Fragen? Feedback? Eigene Erfahrungen teilen? Schreib mir gerne: