Mein erstes Machine Learning Projekt: Was ich beim Klassifizieren von Früchten gelernt habe
Wie ich mit AutoML in wenigen Stunden ein funktionierendes Modell baute – und warum 100% Accuracy nicht immer gut ist.
Einleitung: Warum dieses Projekt?
Als ich mein erstes Data-Science-Projekt gestartet habe, stand ich vor einer einfachen, aber entscheidenden Frage: Wo fängt man eigentlich an?
Klar, der Anfang ist immer schwierig – egal bei welchem Projekt. Aber bei Data Science ist es wichtig, am Anfang den Datensatz zu verstehen. Sowohl inhaltlich als auch explorativ. Wie sehen die Daten aus? Wie ist die Verteilung? Gibt es Auffälligkeiten? Dieser Schritt ist außerdem als Vorbereitung notwendig bevor ein Maschinen Learning Algorithmus eingesetzt wird.
In diesem Artikel nehme ich dich mit durch meinen Workflow: von der Explorativen Datenanalyse (EDA) über die Datenaufbereitung bis hin zum Prototyping mit AutoML. Mit PyCaret – einem Tool, das verschiedene Algorithmen automatisch vergleicht – konnte ich schnell herausfinden, welcher Ansatz am besten zu meinen Daten passt.
Wenn du wissen möchtest, wie ein praxisnaher Einstieg in ein Data-Science-Projekt aussieht, bist du hier genau richtig. Und wenn du erfahren willst, warum 100% Accuracy kein Grund zum Feiern ist, sondern eher ein Warnsignal – dann erst recht.
Was war das Ziel?
Ich wollte verstehen, wie man ein Machine-Learning-Projekt von Anfang bis Ende durchführt. Nicht nur Code schreiben, sondern den gesamten Prozess einmal durchlaufen.
Meine Aufgabe: Ein Modell bauen, das 20 verschiedene Fruchtarten erkennen kann. Also zum Beispiel unterscheiden, ob es sich um einen Apfel, eine Banane oder eine Wassermelone handelt – basierend auf Eigenschaften wie Größe, Gewicht und Farbe.
Mein Tech-Stack:
- Python als Programmiersprache
- Jupyter Notebooks zum Experimentieren
- PyCaret für schnelles Prototyping
- pandas, numpy, matplotlib, seaborn und scikit-learn für Datenverarbeitung und Modelle
Die Daten: Was habe ich eigentlich?
Bevor man irgendwas baut, muss man wissen, womit man arbeitet. Mein Datensatz kommt von Kaggle und enthält 10.000 Einträge zu 20 verschiedenen Früchten.
Was weiß ich über jede Frucht?
- Wie groß sie ist (in cm)
- Wie schwer sie ist (in Gramm)
- Was sie kostet
- Welche Farbe sie hat
- Welche Form (rund, oval, länglich)
- Wie sie schmeckt (süß, sauer, usw.)
Das Erste, was mir aufgefallen ist: Die Daten sind verdächtig sauber. Keine fehlenden Werte, alles schön ausgefüllt. Das sieht man in der echten Welt selten – vermutlich wurde der Datensatz synthetisch erstellt. Aber für ein Lernprojekt: perfekt!
Schritt 1: Die Daten kennenlernen (EDA)
EDA steht für “Explorative Datenanalyse”. Klingt fancy, bedeutet aber einfach: Sich die Daten genau anschauen, bevor man loslegt.
Sind alle Früchte gleich oft vertreten?
Wenn ich 9.000 Äpfel und nur 10 Bananen hätte, wäre das ein Problem. Das Modell würde einfach immer “Apfel” raten und trotzdem oft richtig liegen. Im Machine Learning bezeichnen Data Scientists dieses Phänomen als Data Imbalance und es gehört zu den wichtigen Analysen.
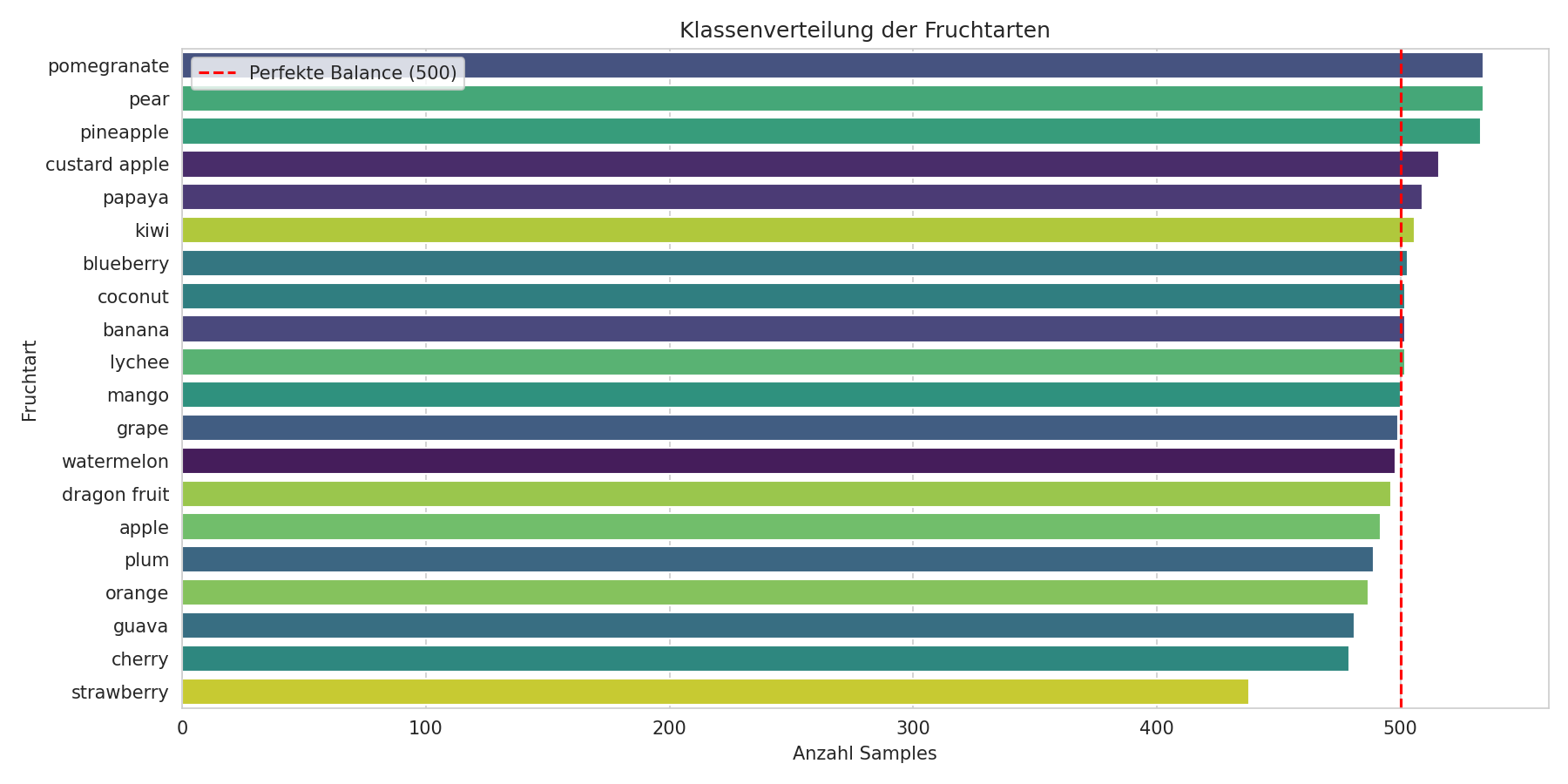
Zum Glück: Jede Fruchtart kommt etwa 500 Mal vor. Die rote Linie zeigt die perfekte Balance.
Wie sehen die Werte aus?
Hier habe ich mir angeschaut, wie Größe, Gewicht und Preis verteilt sind:
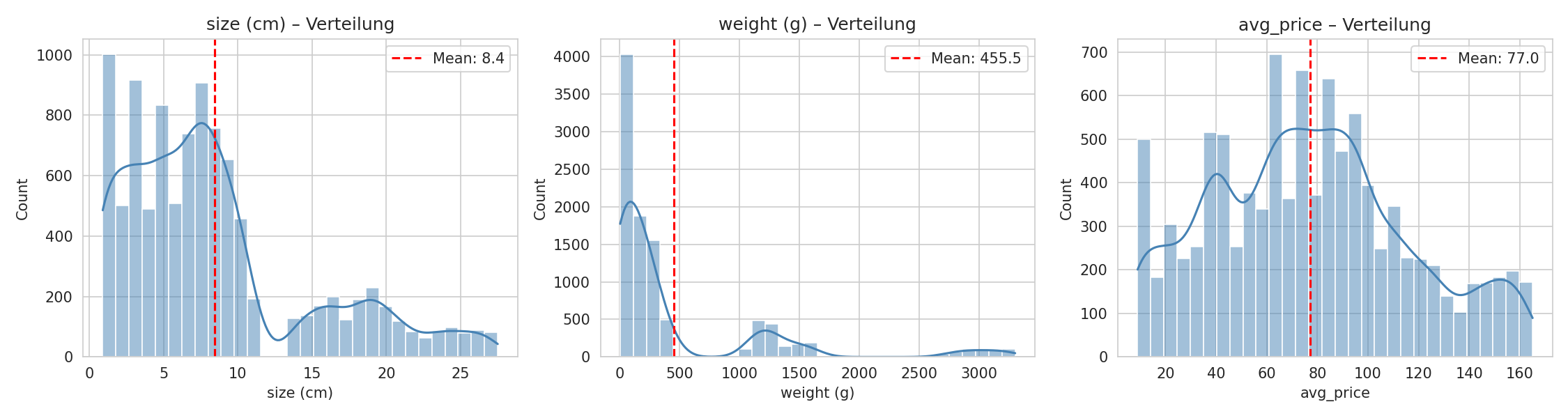
Was sofort auffällt: Es gibt mehrere Gipfel in den Diagrammen. Das macht Sinn – eine Blaubeere wiegt eben nicht so viel wie eine Wassermelone. Diese Unterschiede sind gut! Sie helfen dem Modell später, die Früchte zu unterscheiden.
Hängen die Eigenschaften zusammen?
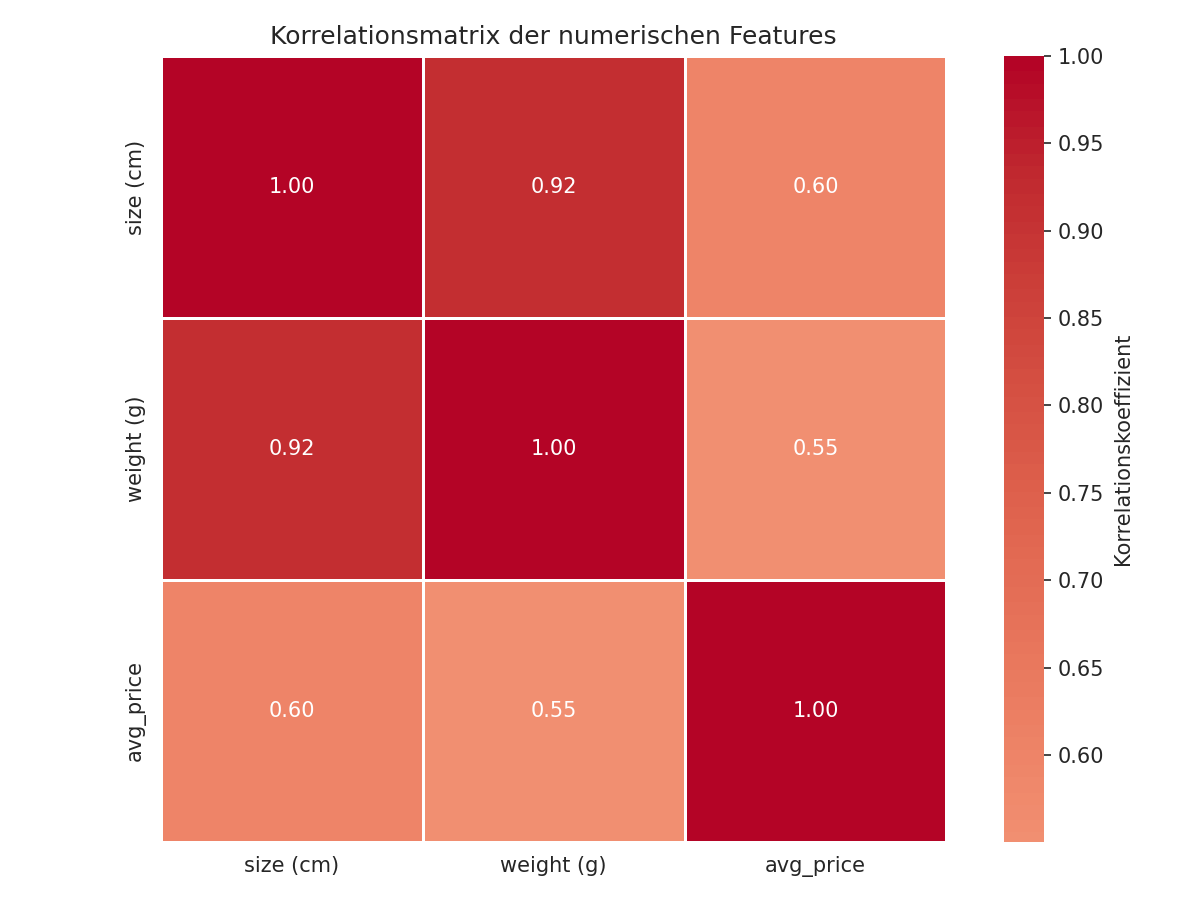
Die Heatmap zeigt: Größe und Gewicht hängen stark zusammen (0.92 von 1.0). Logisch – größere Früchte sind schwerer. Das ist nicht schlimm, aber gut zu wissen.
Kann man die Früchte überhaupt unterscheiden?
Die wichtigste Frage: Wenn ich die Daten in einem Diagramm plotte – sehe ich dann klare Gruppen?
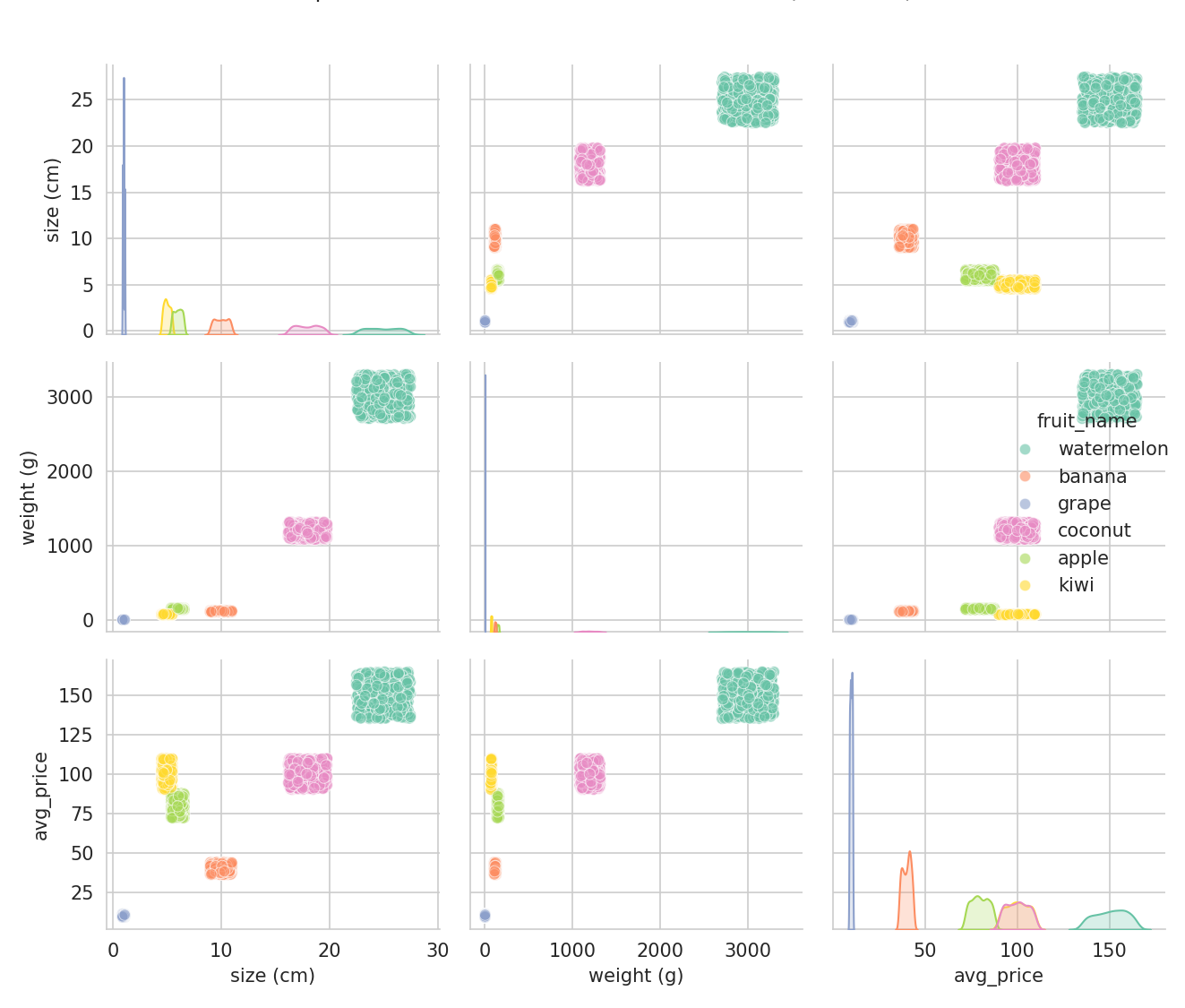
Ja! Jede Farbe ist eine Fruchtart, und sie bilden schöne, getrennte Wolken. Wassermelonen (die großen, schweren) sind klar von Trauben (klein, leicht) unterscheidbar. Das ist ein gutes Zeichen besonders für Verwendung von baumbasierte Methoden!
Schritt 2: Welche Eigenschaften nutzen wir?
Nach der EDA wusste ich: Alle Eigenschaften können helfen, die Früchte zu unterscheiden. Aber eine hat mich nachdenklich gemacht.
Der Preis: Ist er wirklich nützlich? Preise ändern sich je nach Land und Jahr. Ein Modell, das auf indischen Preisen trainiert wurde, würde in Deutschland nicht funktionieren.
Genau solche Überlegungen muss man zu Beginn eines Projekts anstellen – die Daten nicht nur technisch, sondern auch inhaltlich verstehen.
Für dieses Lernprojekt habe ich den Preis trotzdem drin gelassen. In einem echten Projekt würde ich ihn wahrscheinlich weglassen.
Schritt 3: Das Modell bauen
Jetzt wird’s spannend! Aber welchen Algorithmus nehme ich? Die Lösung ist “Prototyping”.
Die Abkürzung: AutoML
Statt jeden Algorithmus einzeln auszuprobieren, habe ich PyCaret benutzt. Das testet automatisch verschiedene Ansätze und sagt mir, welcher am besten funktioniert.
from pycaret.classification import setup, compare_models
# Daten vorbereiten
clf = setup(data=df, target='fruit_name')
# Alle Modelle vergleichen
best_model = compare_models()
Für dieses Projekt habe ich mich auf baumbasierte Algorithmen konzentriert – also Decision Tree, Random Forest und ähnliche. Warum? Die EDA hat gezeigt, dass die Früchte klar trennbare Gruppen bilden. Genau dafür sind Entscheidungsbäume ideal: Sie lernen Regeln wie “Wenn größer als 20 cm und schwerer als 2 kg → Wassermelone”.
Ein paar Zeilen Code – und PyCaret testet alles durch.
Das Ergebnis
| Modell | Erkennungsrate |
|---|---|
| Decision Tree | 100% |
| Random Forest | 100% |
100% bei allen? Das klingt zu gut, um wahr zu sein. Und genau das war es auch.
Der Plot Twist: 100% ist ein Problem
Ein perfektes Ergebnis sollte misstrauisch machen. Hat das Modell wirklich verstanden, was eine Birne ist? Oder hat es sich nur gemerkt: “Wenn grün und oval, dann Birne”?
Der Test
Ich habe neue Testdaten synthetisch erstellt, bei denen die Eigenschaften leicht verändert habe:
- Birnen, die gelb statt grün sind
- Kiwis, die grün statt braun sind
Das Ergebnis war ernüchternd:
| Testdaten | Erkennungsrate |
|---|---|
| Original (wie Trainingsdaten) | 100% |
| Mit leichten Abweichungen | 35% |
Von 100% auf 35%! Das Modell hat nicht “Frucht erkennen” gelernt, sondern nur die exakten Muster aus den Trainingsdaten auswendig gelernt. In der Fachsprache nennt man das Overfitting – das Modell ist zu stark auf die Trainingsdaten spezialisiert.

Das Diagramm zeigt, worauf das Modell am meisten achtet. Form und Größe sind wichtig – aber auch Farbe. Und genau da liegt das Problem: Eine gelbe Birne? Kennt das Modell nicht.
Die Lösung
Was passiert, wenn wir die problematischen Eigenschaften (Farbe, Form, Geschmack) weglassen und nur Größe, Gewicht und Preis verwenden?
| Ansatz | Erkennungsrate |
|---|---|
| Alle Eigenschaften | 35% |
| Nur Zahlen | 93% |
Boom! Ohne die “unzuverlässigen” Eigenschaften funktioniert es viel besser. Natürlich könnte man hier noch weitermachen: verschiedene Kombinationen testen, vielleicht Farbe doch drin lassen und nur Form weglassen. Aber das war nicht das Ziel dieses Projekts – mir ging es darum, den grundlegenden Workflow zu verstehen, nicht das perfekte Modell zu bauen.
Was ich daraus gelernt habe
1. Neben dem Algorithmus ist die Datenqualität wichtig
Ob Decision Tree oder Random Forest – beide hatten das gleiche Problem. Die Lösung lag nicht im Modell, sondern in den Daten. Auch stundenlanges Feintuning an den Modell-Einstellungen hätte hier nichts gebracht.
2. 100% sollte skeptisch machen
Perfekte Ergebnisse bedeuten oft: Das Modell hat auswendig gelernt statt verstanden. Immer mit realistischen Testdaten prüfen!
3. Die richtigen Eigenschaften wählen
Welche Eigenschaften ich nutze, macht einen riesigen Unterschied. In meinem Fall: 35% vs. 93%.
4. Zeit in die Datenanalyse investieren
Ohne EDA hätte ich die Probleme erst viel später entdeckt. Die Zeit für’s “Daten anschauen” ist nie verschwendet.
5. AutoML ist super für den Einstieg
PyCaret hat mir in Minuten gezeigt, was funktioniert. Für den Anfang perfekt – später kann man dann tiefer einsteigen.
Fazit
Was ich geschafft habe:
- ✅ Ein komplettes ML-Projekt von Anfang bis Ende
- ✅ Verstanden, warum Datenqualität so wichtig ist
- ✅ Gelernt, dass “perfekte” Ergebnisse hinterfragt werden sollten
Was als Nächstes kommen könnte:
- Mehr Variationen in die Trainingsdaten bringen
- Weitere Algorithmen ausprobieren
Die wichtigste Erkenntnis in diesem Projekt: Ich habe verstanden, wie man an solche Projekte herangeht. Wie wichtig es ist, die Daten zuerst zu analysieren, bevor man sich für eine Vorgehensweise entscheidet – und warum man immer mit realistischen Testdaten prüfen sollte.
Code & Ressourcen
Wenn du selbst reinschauen möchtest – der komplette Code ist auf GitLab:
🔗 git.tellaev.de/stellaev/fruit-classification
Dort findest du:
- Alle Jupyter Notebooks
- Die Umgebungsdateien zum Nachbauen
- Sämtliche Visualisierungen
Kontakt
Fragen? Feedback? Eigene Erfahrungen teilen? Schreib mir gerne:
Dieser Artikel ist Teil meiner Data-Science-Lernreise. Weitere Projekte folgen!